Introduction à la fouille de textes dans les humanités numériques
Conférencier invité: Dominic Forest
Qu’est-ce que l’on entend par fouille de textes?
Pourquoi fouiller des données?
Depuis ~50 ans, on assiste à l’informatisation des connaissances et plus largement de toutes les activités humaines (transactions financières, interactions sur les médias sociaux, etc.). Lorsqu’on informatise un processus, cela permet d’en récolter des données.
La performance accrue des systèmes informatiques aujourd’hui permet de gérer des plus grandes masses de données.
Ça coûte cher développer des logiciels, des applications, des systèmes informatiques centraux.
Compétitivité informationnelle: aujourd’hui, on s’est rendu compte que l’information peut être monnayable. Les organisations qui détiennent des informations (ex. entreprise œuvrant dans le numérique) ont une grande valeur, même si elles sont déficitaires.
Fouille de données
Les données sont souvent sous forme de textes, mais il y a aussi d’autres formats comme des images.
Les données textuelles sont vues comme étant un sous-ensemble des données en général: elles ont des particularités (vis-à-vis des données non textuelles). Les premières techniques avaient été développées pour des données non textuelles, elles ont ensuite été transférées aux données textuelles.
Forage de données, extraction de connaissances dans des bases de données:
L’ECBD désigne le processus ==non trivial== conduisant à la découverte des informations implicites, inconnues jusqu’alors et potentiellement utiles et compréhensibles à partir des données.
(Piatetsky-Shapiro, 1991)
L’ECBD est le processus non trivial pour découvrir des ==motifs valides==, nouveaux et potentiellement utiles et compréhensibles à partir de données.
(Fayyad, 1996)
Note: ce n’est pas toute analyse de données pas une activité de fouille.
La co-occurrence d’éléments dans deux ensembles de données – est-ce qu’on peut retrouver deux éléments qui co-occurrent souvent ensemble? (Souvent utilisé en marketing.)
Exemple: le panier d’épicerie. En entrant dans une épicerie commune, on se retrouve généralement dans les fruits et légumes. Le lait sera généralement dans le coin opposé à l’entrée. L’allée des couches et généralement contigüe à l’allée de la bière. (Ce sont des stratégies marketing, on peut les constater assez facilement.)
Évaluation des motifs
Exemple: un modèle de fouille de données par Target a permis d’identifier les comportements d’une femme avant qu’elle n’accouche ou soit enceinte (envoi d’échantillons de produits de maternité avant le moment venu). On a repéré des motifs en étroite corrélation avec le moment où la femme tombe enceinte.
Dimension informatique importante:
- intelligence artificielle
- apprentissage machine
- statistiques
- systèmes de bases de données (entrepôts)
Particularité: application sur des données structurées (comme les livres dans un catalogue de bibliothèque).
Plein d’applications en ce moment, c’est une discipline qui a le vent dans les voiles.
Applications
- Gestion de l’offre (ex. sur Amazon, on propose des ouvrages connexes selon les achats effectués)
- la gestion des promotions (en fonction de l’historique d’achats)
- positionnement de produits
- prédiction de l’évolution de stocks (ex. la gestion des stocks chez Walmart, où les marchandises étaient envoyées avant de tomber en rupture de stock)
- système de recommandations
- détection de la fraude
- l’attribution de crédit (aujourd’hui complètement automatisé, la rentabilité fiscale est déjà estimée, on n’a pas besoin de fournir des renseignements à la main)
- évaluation de l’assurabilité médicale (ex. âge auquel on va mourir, voire à l’année près)
- recrutement sportif
- prédiction des revenus
Text mining
Fouille de textes, foragse de textes, text mining
La fouille de textes est la découverte (à l’aide d’outils informatiques) de nouvelles informations en extrayant différentes données provenant de plusieurs documents textuels. Un élément fondamental de ce processus réside dans les relations identifiées entre les informations extraites afin d’identifier de nouveaux faits ou de nouvelles hypothèses à explorer.
(Hearst, 2003, trad. Dominic Forest)
Plusieurs découvertes ont été faites sans passer par des processus empiriques traditionnels. On pourrait découvrir certaines informations à partir d'inférences, assistées par des ordinateurs qui traitent plus rapidement et efficacement des masses de données.
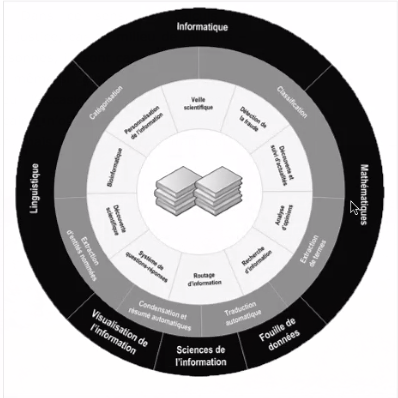
Modélisations du domaine
La fouille de textes est le fruit de plusieurs disciplines.
Démarche méthodologique
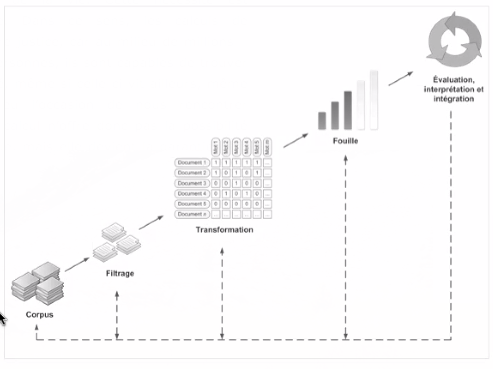
Réfléchir au format d’encodage des données.
- Corpus: rassembler des documents, des textes bruts
- Filtrage: on nettoie le corpus, on garde ce qu’on veut.
- Transformation: traduction des textes de départ en format numérique, selon les critères dont on veut tenir compte dans l’analyse.
- Fouille
- Évaluation, interprétation et intégration
Le processus n’est pas que linéaire, il est généralement très itératif, caractérisé par des allers-retours.
Classification automatique
Pour un ensemble de livres, on peut faire différents regroupements: par taille, par couleur de couverture, par sujet, par collection, etc.
Processus d’organisation supervisé dans le cadre duquel une ou plusieurs catégories (thématiques) sont attribuées à chacun des documents. Projection d’un plan de classification (un ensemble de catégories structurées) sur des documents afin d’attribuer à chaque document une ou plusieurs étiquettes (thématiques) représentant le contenu de chacun de cds documents.
Apprentisage: mémorisation et généralisation.
Text categorisation (also known as text classification, or topic spotting) is the task of automatically sorting a set of documents into categories from a predefined set. This task has several applications, including automated indexing of scientific articles according to predefined thesauring of technical terms, filing patents into patent directories, selective dissemination of information consumers, automated population of hierarchical catalogues of Web resources, spam filtering, identification of document genre, authorship attribution, survey coding, and even automated essay grading.
(Sebastiani, 2005, p. 109)
Application à l’analyse du discours politique
Il y en a une infinité.
L’analyse du discours politique
La diffusion des discours politiques officiels se fait surtout sur les plateformes numériques. Ça coûte moins cher s’adresser aux électeurs par les voies numériques, et par conséquent une augmentation des messages envoyés par ce canal. Augmentation des documents diffusés. Il y a trop de documents pour tout lire.
Les outils de texte analytique pourraient-ils nous permettre de faire le tri, voire d’avoir accès aux résumés?
Corpus
Cinq principaux partis fédéraux, communications évaluées dans les types de documents suivants:
- plateformes officielles
- communiqueées
- billtes de blogue
(pas réseaux sociaux)
Information totalement contrôlée par les partis politiques (pour réduire le bruit dans les données).
Données récupérées manuellement (longue tâche de moine).